NUS Sentiment @ Hack&Roll 23
Jan 19, 2023
My friends Minh Tuan, Jake, Utkarsh and I were one of the selected winners among over 400 participants and 100 submissions at Hack&Roll 2023.
This post will detail what we built in the 24 hour duration.
If you’d like, you can also view our Devpost submission here and the actual app here
Edit (23/1/2024): Due to changes in the Reddit API, this app is officially dead, but the idea lives on!
The Problem
My favorite thing about Hack&Roll is the no problem statement concept as there isn’t a specific theme you are forced to cater to.
This time around I suggested to my team that we should build a tool that would help students find information faster and more effectively. I had always hated vanilla Reddit search because it works on naive exact matching [1].
Often times, it would be more effective using Google instead and appending ‘reddit’ as a suffix like so: rvrc reviews nus reddit
In addition, I also wanted a way of getting an instant overall insight on a topic instantly, instead of having to manually parse through countless threads. [2]
The Idea
To solve [1], we needed a semantic search engine. For [2], we opted to implement a sentiment classifier for each post.
The Solutions
UI
We decided to use Streamlit to built the UI for this application. It integrated nicely with the rest of our stack and wouldn’t require a seperate REST layer to a backend. Plus, Streamlit Cloud gives free hosting.
Reddit Scraper
Scraping was done via the praw Reddit API wrapper for Python.
A post here refers to both the main post and it’s associated replies. praw represents the post and comments in a tree-like data structure. If a main post has replies, then each reply can also have multiple replies. Therefore to parse every post, we need to do a traversal.
For a large subreddit, this could take an extremely long time to parse. We did not run into any issues because the NUS subreddit is only a few years old, but YMMV.
reddit = init_reddit_agent()
# there isn't likely to be a new post for given key within a hour delta
# so we cache the result for an hour
@st.experimental_memo(ttl=60*60)
def scrape(keyword: str) -> pd.DataFrame:
data = []
for post in nus_sub.search(keyword):
comment = post.comments
comments_list = comments.list()
# add the body of the post itself
data.append(
(
post.title,
post.author,
datetime.fromtimestamp(post.created_utc),
post.selftext,
post.url,
post.id
)
)
# DFS
while len(comments_list) > 0:
comment = comments_list.pop(0)
if isValidComment(comment): # check if post is by a bot or [deleted]
data.append(
(
post.title,
comment.author,
datetime.fromtimestamp(comment.created_utc),
comment.body,
post.url,
comment.id
)
)
elif isinstance(comment, praw.models.MoreComments):
comments_list.extend(comment.comments())
return pd.DataFrame(
data,
columns=["thread_title", "author", "created_at", "post", "url", "id"]
)By storing the url + id of each post, we are able to redirect users to the source, leaving no doubts that the content is in fact real.
Sentiment Analysis
Since this was a 24h hackathon, we obviously did not have time to fine tune a model for this specific purpose. We used cardiffnlp/twitter-roberta-base-sentiment straight from the HuggingFace hub without any modifications as it was trained on a similar objective and was lightweight enough to be deployed on a 1GB VRAM machine.
from transformers import pipeline
nlp = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer,
device=device
)One thing to note is that the a single post can be quite lengthy and may exceed the model’s context length. The most naive but common way to overcome this issue is by simply truncating.
tokenizer_kwargs = {"truncation": True, "max_length": 512}
# posts: List[str]
sentiments = nlp(posts, **tokenizer_kwargs)Vector Search
Pinecone was used as the vector database. sentence-transformers/all-MiniLM-L6-v2 was the embedding model we used to map the contents of each post into a 384 dimensional vector representation.
Embedding models are trained such that semantically similar sentences are closer to each other in the n-dimensional space. Closer in this context may refer to distance metrics such as norm or similarity metrics such as cosine similarity
import pinecone
from sentence_transformers import SentenceTransformer
pinecone.init(
api_key= "<PINECONE_API_KEY>",
environment="us-west1-gcp" # this is the only free of charge region
)In this scenario we used cosine similarity as the search metric.
pinecone.create_index(
index_name,
dimension=384,
metric="cosine"
)
# store a reference to the index
index = pinecone.Index(index_name)
# initialize the sentence-transformer model
enc = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')After inserting data into the database, we are now ready to do a search.
query = "<some search string given by the user>"
# embed the query
xq = enc.encode(query).tolist() # converts the numpy array back to a Python list
# search against records in the database
res = index.query(xq, top_k=K, include_metadata=True)Internally, you can think of Pinecone computing the cosine similarity of the query vs all records in the database , then giving you the top K records with the highest cosine similarity.
where is the query vector whereas
This way of computing against the entire database every time is inefficient. Pinecone and many other vector database solutions implement indexing algorithms such as HNSW for quicker retrieval at the cost of memory.
The Result
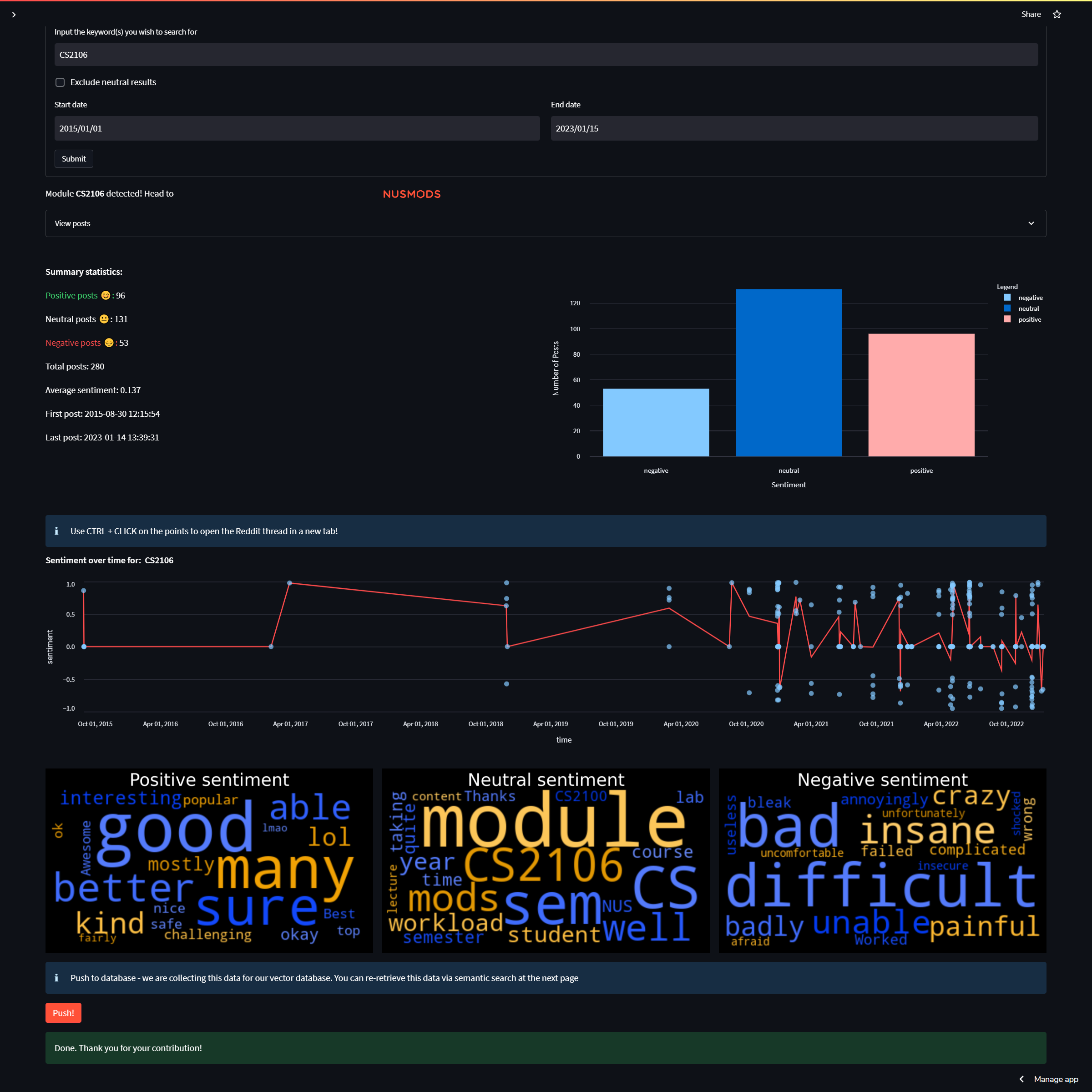
The final step was to display all our hard work above. We used plotly, altair for the charts & textblob for the WordCloud’s split by sentiment classification.
Users are able to instantly see the distribution of sentiments for a given topic, as well as it’s evolution over time. Clicking on the blue dots of the time-series plot will also lead to the exact post or reply on Reddit.
These results are pushed into Pinecone, where users can then perform natural language queries.